SQL 语句的执行顺序,以及优化的方向思考
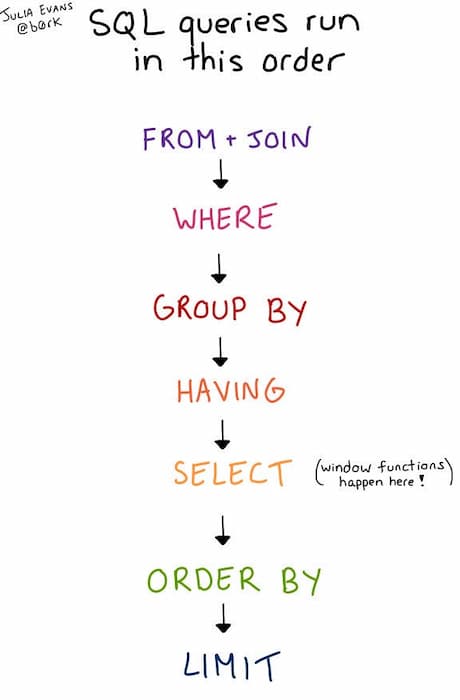
这是一条SQL的执行顺序
可以看到JOIN和WHERE在早期执行,所以优化的重点往往也在这里。数据库的查询性能一般受CPU检索能力+I/O设备的读写速度影响,所以要提高查询性能最简单粗暴的方式就是 换更强的CPU(这样逻辑判断就更快),或者增加存储设备的性能(例如机械盘换SSD)。这种方式有点类似于以力破巧,简单粗暴有效果。
当硬件都没法再提高的情况下,就要从思路上来解决问题了。索引就是一个简单的提高查询性能的方法,具体原理就是把关键数据的位置单独保存一下,类似于一本书的目录,没有目录的时候找一篇文章需要翻遍整本书,但是有目录了以后,就可以根据目录直接翻到对应页码。不过要注意,索引也是有副作用的,首先是降低写入性能,因为制作目录需要单独的计算,还有就是不要滥用索引,只索引最需要的字段(往往是查询条件最常见的字段),这里还有联合索引的概念,就不具体展开了。
根据执行顺序,要小心的考虑join的方向(不同的join出来的结果不同),要join出来(能够包含查询需要的数据)最小的结果集,这样CPU的性能就会减少浪费。然后是仔细斟酌where的条件,也是避免无端的CPU性能浪费,原则就是尽可能在早期筛掉明显不符合查询条件的结果,减少CPU判断次数。
GROOUP BY和HAVING也是比较早期的执行过程,所以要慎用,这个非常影响性能,不过好在它在where之后,如果在where之前,那就是个灾难了,在对全部数据集做分组,不敢想象会有多慢。
SELECT以前不太建议条件直接用 * 但现在基本没问题了 ,查询优化器会自动优化了。 所以优化SQL的整体方向就是,减少硬件的读写和判断,尽可能在早期筛掉无效结果,减少结果集的大小 但这个想法如果不经过实践应该会比较难理解,需要在具体工作中多分析思考尝试。